About Critique
Built for code that has to hold.
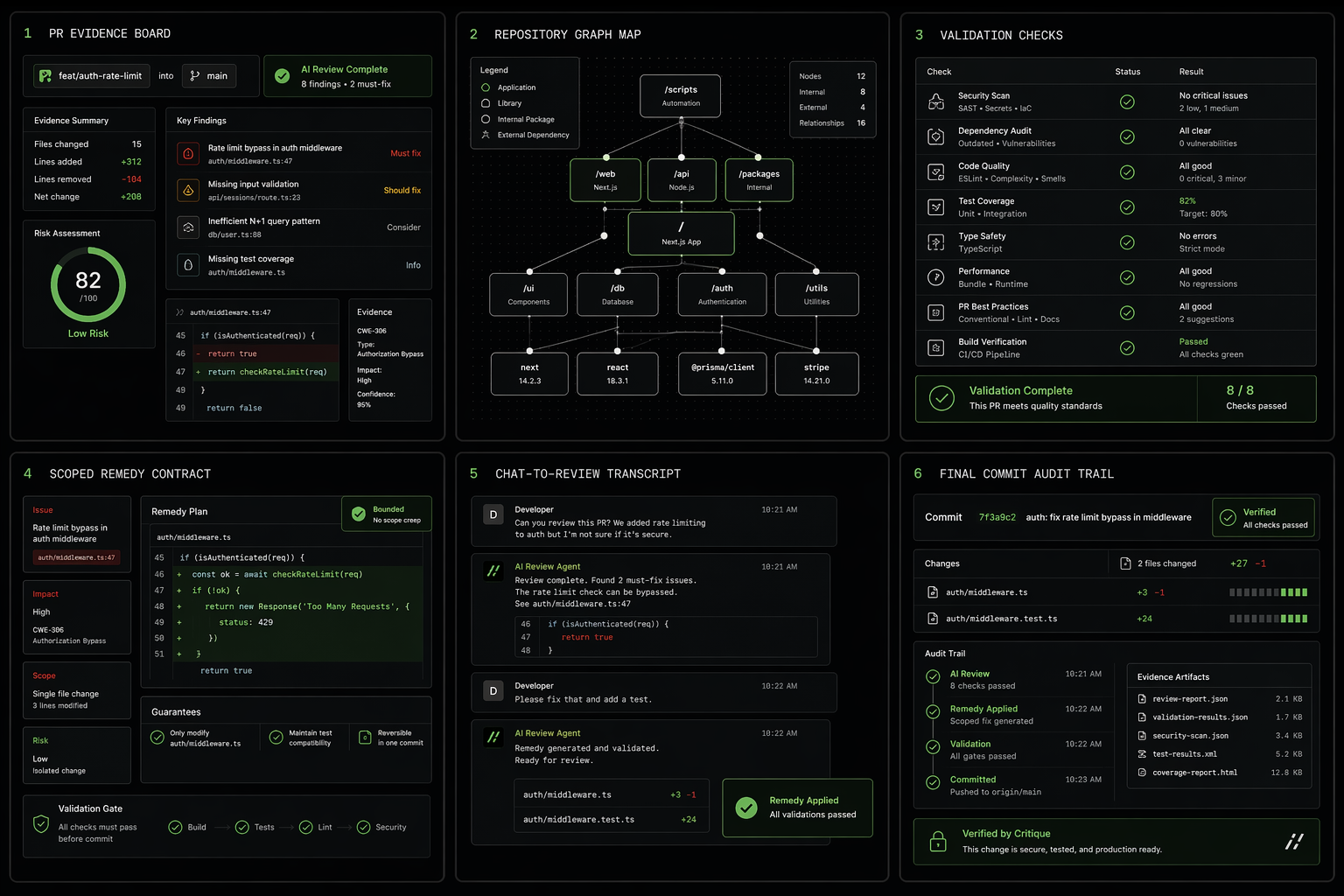
AI agents write code. Critique verifies it in a sandbox before you merge. Critique is an Automated code verification platform for GitHub pull requests — not another comment bot on your diff.
We gate untrusted changes, run evidence-backed review, enforce merge policy, repair with proof, and expose the same control plane over the Dashboard, GitHub, and Platform API — one Change Passport per pull request.
Change Passport
One governed record per pull request
Merge boundary
Gate, evidence, policy, repair
Platform API
Same control plane everywhere
Change control
Not just a code review CI tool.
Critique treats the Change Passport as the product object: provenance, risk, evidence, policy decisions, remedy proof, and memory on one merge-boundary record. Review runs are commit-level evidence generators inside that passport.
Linked context
Chat, review, and remedy share repository state instead of re-explaining the PR.
Checkpoint first
Policy gates run before the review swarm spends on untrusted shape.
Visible artifacts
Findings, scope, and handoff contracts stay on the trail.
Bounded execution
Automation stops at agreed scope — not an open-ended rewrite.
Merge-boundary phases
Phase 1
Gate
- When
- Before the review queue
- Check
- Critique / Checkpoint
- What it does
- Fast, cheap firewall rules
Phase 2
Review
- When
- During the run
- Check
- Critique / Review
- What it does
- Multi-model specialists + lead verdict
Phase 3
Merge
- When
- After evidence
- Check
- Critique / Merge Policy
- What it does
- Enforceable merge rules with proof
The loop
Chat, review, then repair.
We started with review because finding the truth has to come before asking automation to act. Checkpoint can gate the PR before the review swarm spends.
Chat
Ask repository questions without starting from zero.
Review
Run a grounded PR critique with specialist lanes.
Remedy
Turn eligible findings into validated branch updates.
Checkpoint modes
- dry-run
Observe policy impact without blocking contributors.
- warn
Surface risk while still allowing the review to continue.
- block
Stop untrusted or malformed PRs before full automation starts.
Platform
One merge boundary. Many surfaces.
Critique is not a single feature — it is a control plane for how AI-authored changes enter your codebase. Each surface below ships in beta and links to operator docs plus the ship log entry where it landed.
Change control
Change Passports, Control Board policy, memory, and merge-boundary governance — not comment-only review.
PR review
Multi-model specialists, evidence contracts, sandbox verification, and `@critique-bot` on pull requests.
Checkpoint
Agent Firewall gates — dry-run, warn, or block — before review spend on untrusted PR shape.
Agent Workspace
Repo-grounded chat, cloud lanes, builder, and repair in one `/workspace` shell.
Critique Intake
Embeddable bug intake: context capture, triage, and agent-ready handoff prompts.
Remedy
Bounded fix execution in an isolated sandbox with patch hash and verification proof.
Merge Gate API
Queue reviews, read passports, and enforce merge policy over HTTP and MCP.
Inference API
OpenAI-compatible chat completions on Critique credits with usage transparency.
Coding Agent API
OpenCode + E2B runs over HTTP with optional draft PR publish.
Skill Marketplace
Browse, publish, and install review lenses with a feedback-driven leaderboard.
BYOK & BYOA
Bring your OpenRouter or CrofAI key, or route fixes to Cursor, Claude, and Codex.
Connections & Insights
Linear, Slack, scoped `crt_` keys, and velocity, cost, and compliance dashboards.
Full index: documentation · version history · Skill Marketplace
Principles
How we decide what ships.
Evidence over vibes
traceA finding should carry enough context for an engineer to verify it fast.
Trust is earned
gateAutomation must show its work, obey scope, and accept when it should stop.
Code before theatre
quietThe interface stays quiet because the work is already complicated.
Taste under pressure
craftDeveloper tools should feel precise even when the system is busy.
Local control
policyTeams choose policies, models, and where execution runs.
Autonomy with boundaries. That is how trust is earned.
Shipping now
Live in beta, shipping weekly.
The list below is the short operator view. Each row in the Platform section above links to docs and the release that introduced it.
- Change Passports — provenance, risk, evidence, policy, and remedy proof per PR
- Control Board — gate, policy, memory, delivery, and learnings in one operator surface
- GitHub App review runs with evidence contracts and specialist lanes
- Agent Workspace — chat, cloud lanes, builder, and repair on one shell
- Checkpoint (Agent Firewall) on the merge boundary
- Remedy with proof bundles and bounded sandbox execution
- Critique Intake — agentic bug intake from user report to handoff
- Platform API v1 — queue reviews, passports, webhooks, and MCP
- Merge Gate API, Inference API, and Coding Agent API
- Agent Skill Marketplace with performance leaderboard
- BYOK (OpenRouter / CrofAI) and BYOA (Cursor, Claude, Codex)
- Insights — velocity, cost, retrospectives, and compliance exports
Start here
Better code. Shipped with confidence.
Connect GitHub, run your next PR through review, and use Remedy when the fix has enough evidence to act.
Contact
Product and account help: support@critique.sh. Founder: Repath Khan (ray@critique.sh).